Search
Tokenization
Tokenization substitutes a sensitive identifier (e.g., a unique ID number or other PII) with a non-sensitive equivalent (i.e., a “token”) that has no extrinsic or exploitable meaning or value. These tokens are used in place of identifiers or PII to represent the user in a database or during transactions such as authentication. The mapping from the original data to a token uses methods—e.g., randomization or a hashing algorithm—that render tokens infeasible to reverse without access to the tokenization system.
Tokenization is not a new technology. In credit and debit card systems, for example, tokenization has long been used to replace data on the card (e.g. the primary account number or PAN), with a unique randomly generated token that can be used to represent the card data in transactions but does not reveal the original card data. This means that the number of systems with access to the original card data is dramatically reduced, and with it the risk of fraud should a system become compromised.
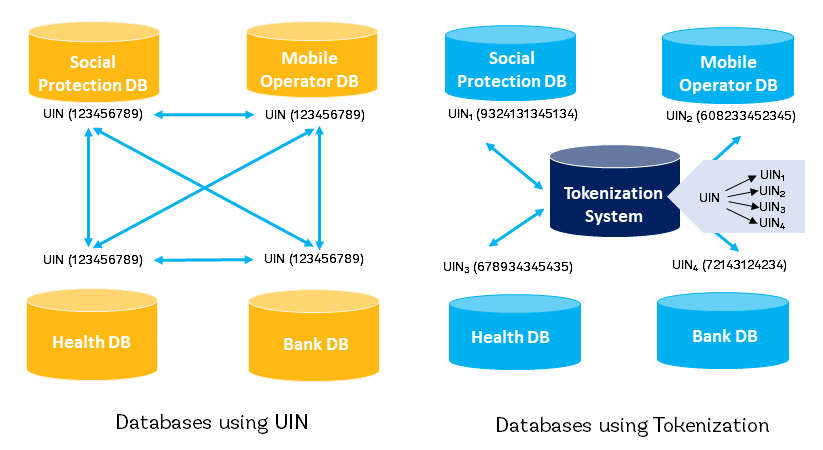
Tokenization can protect privacy by ensuring that only tokens, rather than a permanent identity number or other PII, are exposed or stored during a transaction. In addition—where the same person is represented by different tokens in different databases—tokenization can limit the propagation of a single identifier (e.g., a unique ID number). This can help limit the ability to correlate a person’s data across different databases, which can be a privacy risk and also increases the possibility of fraud.
The essential features of a token are: (1) it should be unique, and (2) service providers and other unauthorized entities cannot “reverse engineer” the original identity or PII from the token. There are two primary types of tokenization:
-
Front-end tokenization: “Front-end” tokenization is the creation of a token by the user as part of an online service that can later be used in digital transactions in place of the original identifier value. This is the approach taken by Aadhaar to create a Virtual ID derived from India’s Aadhaar Number, as described in Box 21). The problem with front-end tokenization is that it is very user driven, requiring users to be digitally literate and technically capable of both understanding why they would need a token and how to create one online. This could easily lead to a digital divide with regard to privacy protection.
-
Back-end tokenization: “Back-end” tokenization is when the identity provider (or token provider) tokenizes identifiers before they are shared with other systems, limiting the propagation of the original identifier and controlling the correlation of data. Back-end tokenization is done automatically by the system without user intervention, meaning that people do not need to do anything manually or understand why they would need to create tokens, eliminating any potential digital divide and protecting identifiers and PII at source. Austria's virtual citizen card is one example of this type of tokenization (see Box 20), and India has also implemented back-end tokenization of the Aadhaar number in addition to its Virtual ID (see Box 21).
|
Box 20. Austria’s sector-specific identifiers The data contained on Austria’s virtual citizen card (CC, see Box 37) is called “Identity Link” and consists of full name, date of birth, cryptographic keys required for encryption and digital signatures, and the “SourcePIN”—a unique identifier created by strong encryption of the 12-digit unique ID (CRR) number. To ensure integrity and authenticity, the Identity Link data structure is digitally signed by the SourcePIN Register Authority at issuance. Access to SourcePIN and cryptographic keys on a CC is protected by PIN. To safeguard user privacy, the eGovernment Act stipulates that different identifiers be used for each of the country’s 26 public administration sections—e.g., tax, health, education, etc.— that a person accesses. A sector-specific personal identifier (ssPIN) is created from the SourcePIN using one-way derivation, a tokenization method through which a sector specific-pin is algorithmically computed from the SourcePIN. Unlike the SourcePIN, the ssPIN can be stored in administrative procedures. Public authorities can use the same ssPIN to retrieve a citizen’s data stored within the same procedural sector, for example, if they need to view the citizen’s records or use it to pre-fill forms. However, authorities do not have access to ssPINs from other sectors. 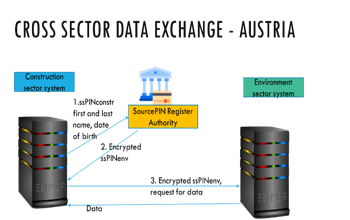
Administrative procedures often require authorities from different sectors work together. If authority “A” requires information about a person from authority “B” in another sector, authority “A” can request sector “B’s” identifier from the SourcePIN Register Authority by providing the identifier from their own sector, the person’s first and last name, and their date of birth. The SourcePIN Register Authority then sends the ssPIN from authority “B” to authority “A” in encrypted form; however, this can only be decrypted by authority “B”. In order to access the data, authority “A” then sends the encrypted ssPIN to authority “B,” which decrypts it and returns the requested data. Source: Privacy by Design: Current Practices in Estonia, India, and Austria. |
Although tokenization and encryption both obscure personal data, they do so in different ways, as shown in Figure 14. In general, tokenization is often simpler and cheaper to implement than encryption and has a lower impact on relying parties, as they do not need to decrypt data in order to use it. Tokens also have the advantage that, because they replace PII rather than hiding it like encryption, it is impossible to recover the original data in the case of a data breach.
Figure 14. Tokenization vs. encryption
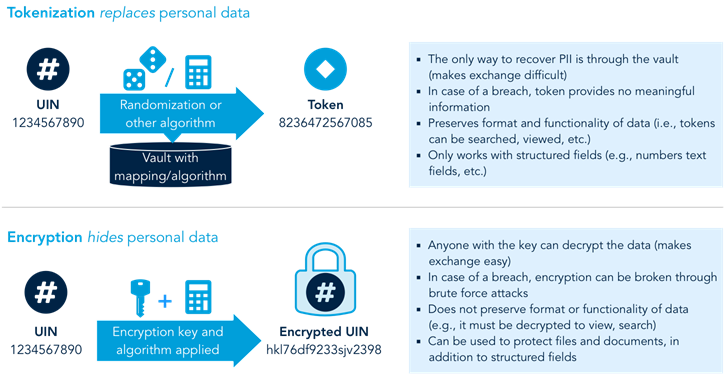
At the same time, however, tokenization requires a means of mapping tokens to the actual identifier or PII data values (e.g. a token vault or algorithm)—with the most obvious options being through cryptography or reference tables. This can create issues with scalability, particularly where there is a need to access the actual user data in order to complete a transaction. For authentication this is not always the case, as there does not necessarily need to be disclosure of any personal data in order to prove that the individual is who they say they are. Implementations such as GOV.UK Verify (see Box 38) and Aadhaar (Box 21) are capable of managing the tokenization of identifiers at scale by avoiding the need to share data.
|
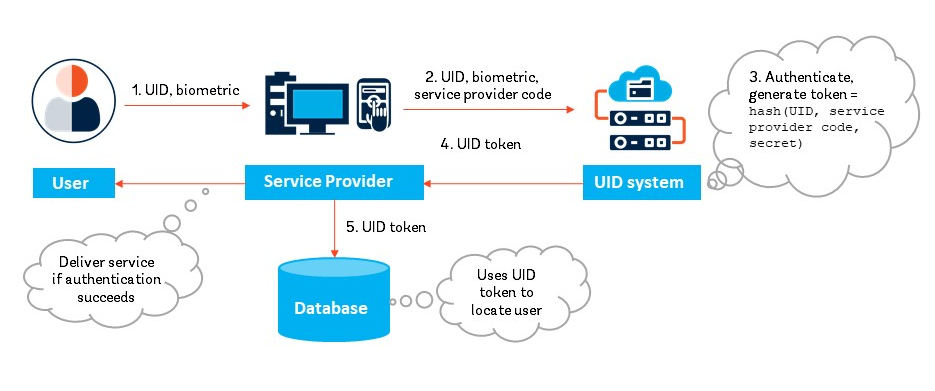
Box 21. India’s Virtual ID and tokenization systems In January 2018, the Unique Identification Authority of India (UIDAI) announced the introduction of two services for the Aadhaar unique ID system: (a) Virtual ID, and (b) UID token and limited KYC. Both features use tokenization to enhance the privacy and protection of Aadhaar holders’ personal data. The virtual ID service involves front-end tokenization. It allows users to keep their unique, 12-digit Aadhaar number hidden from service providers by generating a random, 16-digit virtual ID number. This requires accessing the resident portal and authenticating themselves using an OTP sent on their registered mobile number. The virtual ID is mapped to the Aadhaar number by UIDAI. Once a person has generated a Virtual ID, they can provide that 16-digit number instead of their Aadhaar number for authentication; new Virtual ID numbers can be generated once every 24 hours. A key privacy-enhancing aspect is that the Virtual ID is temporary and revocable. As a result, service providers cannot rely on it or use it for correlation across databases. Users can change their Virtual ID as needed, just as one would reset their computer password/PIN. As a complement to the virtual ID, UIDAI also introduced back-end tokenization to address the storage of Aadhaar numbers in service provider databases. Now, when a user gives their Aadhaar number or Virtual ID to a service provider for authentication, the system uses a cryptographic hash function to generate a 72-character alphanumeric token specific to that service-provider and Aadhaar number which can be stored in the service provider database. Because different agencies receive different tokens for the same person, this prevents the linkability of information across databases based on the Aadhaar number. Only UIDAI and the Aadhaar system knows the mapping between the Aadhaar number and the tokens provided to the service providers. Subsequently, when the user authenticates with the service provider, the ID system again computes the token using the same hash function with Aadhaar number, service provider code and the secret message as inputs and generates the same UID token. The UID token would always be same for the given combination of Aadhaar number and service provider code. The combination of the Virtual ID and UID token increases the level of privacy and security, as shown in the figure below:
Certain service providers (“global AUAs”) are allowed to store and use Aadhaar numbers and use the full eKYC API, which returns both the Aadhaar number and the token, along with the KYC data. Other service providers (“local AUAs”) can only use the limited eKYC API using the token, and do not receive the Aadhaar number. This will limit the linkability of personal information across databases, as shown in the figure below.
Source: Privacy by Design: Current Practices in Estonia, India, and Austria. Find more information on Virtual ID, tokenization, and limited eKYC in India here. |