Search
Unique ID Numbers
In any ID system, identifying numbers—including unique ID numbers (UINs), also sometimes known as national ID numbers (NINs)—are the most basic type of identifier. They are issued automatically when a person enrolls, and their default function is to serve as a record locater or index within the system to facilitate back-end operations such as linking different tables within a database.
In the context of foundational systems, ID numbers are considered to be “unique” when:
-
the number-generating process ensures that no two people within the system share the same number; and
-
a deduplication process ensures that the same person does not have multiple identity records or numbers (i.e., that they are unique in the database).
In addition to their function as back-end identifiers, however, ID numbers have been used for authentication as a type of credential. In this role, they serve a similar function to that of a username: they are information that a person presents to a relying party—along with one or more authenticators such as biometrics, passwords, OTPs, PINs—to say “this is who I am.” The system then uses the ID number (or username) to look up the person’s record (or account) in a database and then verify the authenticators they have provided against that record. As discussed above in the case of India, using a unique ID number as an identifier during authentication could eliminate the need for physical credentials. However, there are certain limitations to this use including the need for connectivity and some people’s preferences for having physical credentials for in-person authentication.
Beyond usability, there are also important data protection concerns with using a “raw” (i.e., the root or original) ID numbers for authentication. Like user names, ID numbers can only be considered credentials in the weak sense, in that they are often widely known or easily discovered. The more these numbers are used across multiple systems, the higher the risks that they can be used to correlate information about a person. This risk is even higher when ID numbers are used as authenticators in addition to identifiers—i.e., when they are treated as a user name (identifier) in some systems, and a password (authenticator) in others. This has happened extensively in the US and UK, where—in the absence of national ID systems—social security numbers (SSNs) have become a de facto authenticator used to prove that a person is who they claim to be for services that lack a stronger authentication mechanism (e.g., asking people to provide the last four digits of their SSN when logging into online banking).
Alongside policy, regulatory, and legal controls that dictate the appropriate use of identifiers in order to avoid this type of function creep and its associated risks, technical measures should be adopted to obscure the ID number when it is used for authentication or other purposes. This may include, for example, using tokenized versions of the identity number—discussed below and in Box 21 on India’s virtual ID system—rather than the original ID number. In addition to evaluating the potential use of the ID number outside of record management, practitioners must also determine the structure of the number itself, which has implications for the system’s ability to protect privacy and personal data.
Number structure
The structure of an ID number—including its format and length—require careful consideration of country context and privacy concerns. In any system, ID numbers can take one of three formats:
-
Random. A random number (technically a “pseudo” random number) is generated using mathematical algorithms and contains no information about the person.
-
Serial. A serial number is assigned based on the order of entry into the system, with the highest number assigned to the most recent enrollee.
-
Coded. A number that contains information about the person, with certain digits coded based on attributes such as birth year, gender, nationality, and location of application.
Historically, many countries adopted coded numbers in their national ID and civil registration systems. In part, this was an innovation that helped standardize and pre-assign these numbers in the context of paper-based systems managed simultaneously by decentralized offices. In this context, coding numbers allowed for disconnected local offices to assign (relatively) unique numbers without knowing which numbers might already have been assigned by a neighboring office.
Figure 28. ID number structure
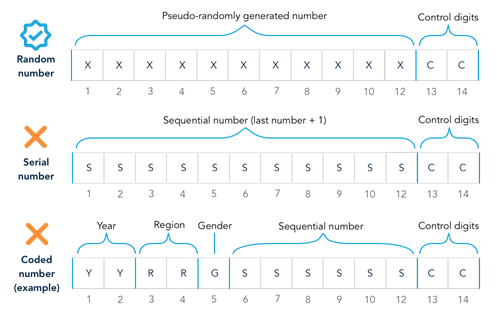
In the digital era, however, randomized numbers are the preferred choice for enhancing privacy and security. Connectivity between registration points, along with the centralized nature of deduplication and advanced computing power, mean that it is now possible to assign unique, random numbers to every person in the ID system. Random numbers offer three primary benefits over coded numbers:
-
They reveal no personal information. By definition, coded numbers reveal information about a person. And while serial numbers reveal less information than coded numbers, they do—by virtue of being ordered—provide a relative indication of age. When accessed by administrators in a database or during authentication, the information these numbers provide could be used for profiling, discrimination, or social exclusion, even if it appears innocuous. For example, a number indicating the region where the individual was born could be used to infer ethnicity or religion if a particular group is predominant in that region. In contrast, random numbers reveal nothing about a person and therefore protect privacy by avoiding the data exposure. For this reason, random numbers are required under multiple frameworks, including Europe’s eIDAS standards (see www.eid.as).
-
They are more secure. Coded numbers make it easier for fraudsters to guess an ID number by narrowing down the possible combinations based on a few known facts about a person. This is a particular concern in the age of social media, where basic information about a person (e.g., their age, name, gender, and location of birth) is relatively easy to determine. Because they contain no information about the person, random numbers (as well as sequential numbers) are not susceptible to this type of attack.
-
They are immutable. In some cases, coded numbers contain information—such as nationality, place of residence, or gender—which may be subject to change over an individual’s lifetime, requiring the numbers to be updated. In contrast, random and serial numbers can be constant from the point of entry (e.g., at birth) to retirement (e.g., after death) for each person in the system.
In addition to format, the length of an ID number has important implications for its utility. Key factors to consider in determining length include:
-
Population size and growth. The number of digits selected should allow for more than enough numeric combinations to provide new (i.e., not recycled), unique numbers to all newborns and new arrivals expected in the foreseeable lifetime of the ID system. For example, an 8-digit number using numerals 0-9 would provide 100 million unique numbers, while 10 digits would provide 10 billion.
-
Use of control digits (or checksums). Control digits are numbers computed from—and then added to—the randomly generated stem via a checksum or hashing function. They are used to check data entry errors (by a human) such mistyped digits, transposition errors, etc. The more complex the hashing or checksum algorithm, the greater the ability to detect more types of errors (and the more control digits required).
-
Usability. While longer numbers are needed to accommodate population growth (and control digits add to this length), excessively long numbers may compromise usability as a common identifier or authenticator—i.e., when people must remember the number, and/or when the number must be frequently entered by hand. This issue may particularly affect people with low levels of literacy.